The Evolving Memory - Understanding the "Hidden State" in RNNs, LSTMs, and Transformers
In sequence machine learning models (RNNs, LSTMs, and Transformers), it is sometimes confusing to talk about “hidden states” because they refer to different structures in the model. In this blog, I would like to compare the concept of hidden state in different models, in order to achieve a better understanding of the advantage and limitation of different models.
RNN: The Simple, Recurrent Memory
In Recurrent Neural Networks (RNN), the hidden state is a straightforward and intuitive concept. It is a vector that encapsulates a summary of the information from all previous time steps in a sequence. At each step, the RNN’s hidden state is updated based on two inputs: the current input element of the sequence and the hidden state from the previous time step.
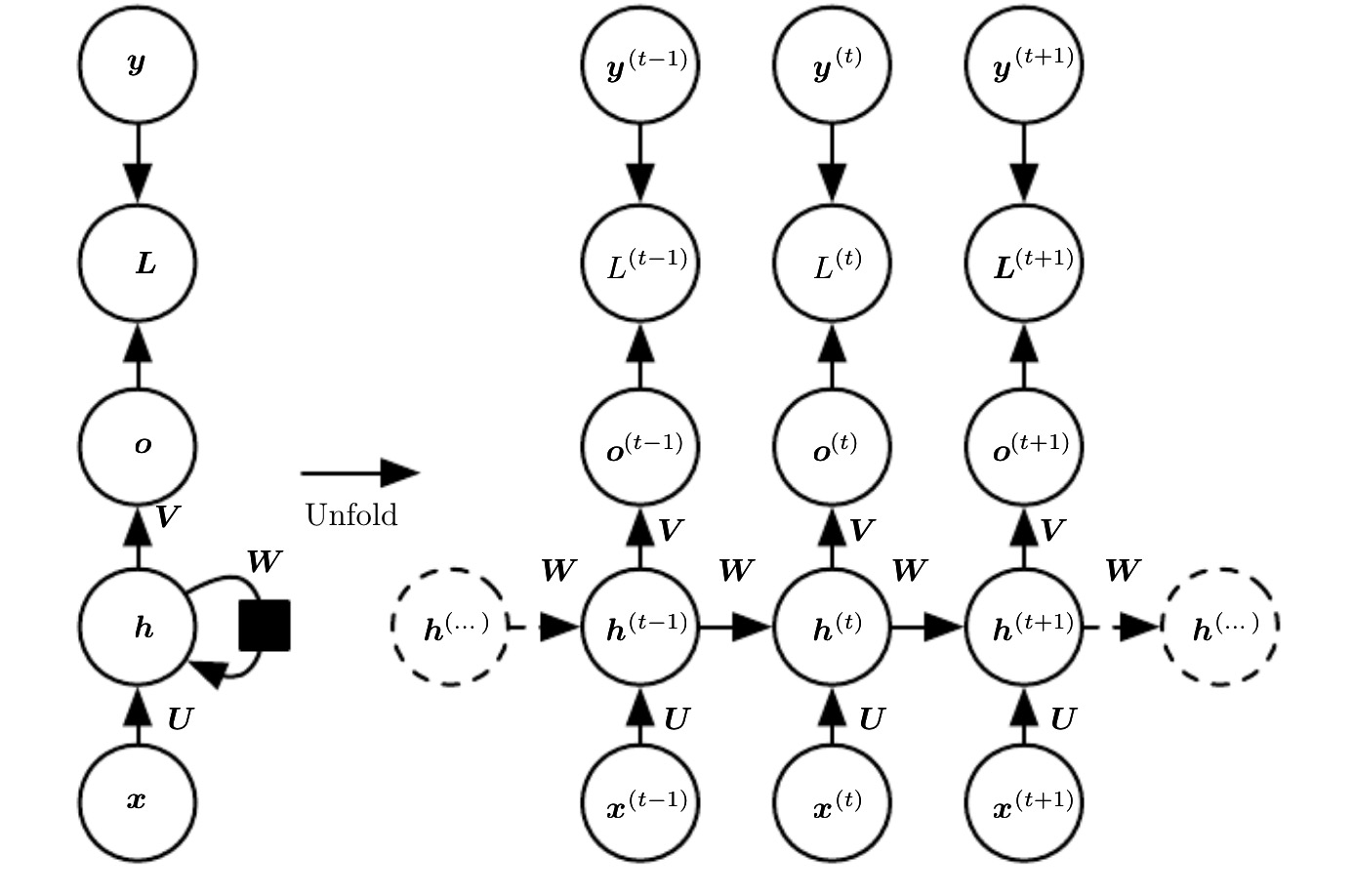 (Figure 1: RNN structure. Taken from Chapter 10 of the book[1].)
(Figure 1: RNN structure. Taken from Chapter 10 of the book[1].)
This process can be visualized as a loop where the network’s output from one step is fed back into itself for the next. The mathematical representation is a simple function:
\[h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b_h)\]where:
- $h_t$ is the new hidden state at time step t.
- $h_{t-1}$ is the hidden state from the previous time step t-1.
- $x_t$ is the input at the current time step t.
- $W_{hh}$ and $W_{xh}$ are weight matrices.
- $b_h$ is a bias vector.
-
tanhis the activation function.
This recurrent nature allows the RNN to maintain a memory of the past. However, this simple architecture suffers from the “vanishing gradient problem,” where the influence of earlier time steps diminishes rapidly over long sequences, making it difficult for the model to learn long-range dependencies. This is solved by the following LSTM structure.
LSTM: A Gated and More Sophisticated Memory
Long Short-Term Memory (LSTM) networks were specifically designed to address the shortcomings of simple RNNs. LSTMs introduce a more complex internal structure within each recurrent cell, featuring a dual-state memory system and a series of “gates” that regulate the flow of information.
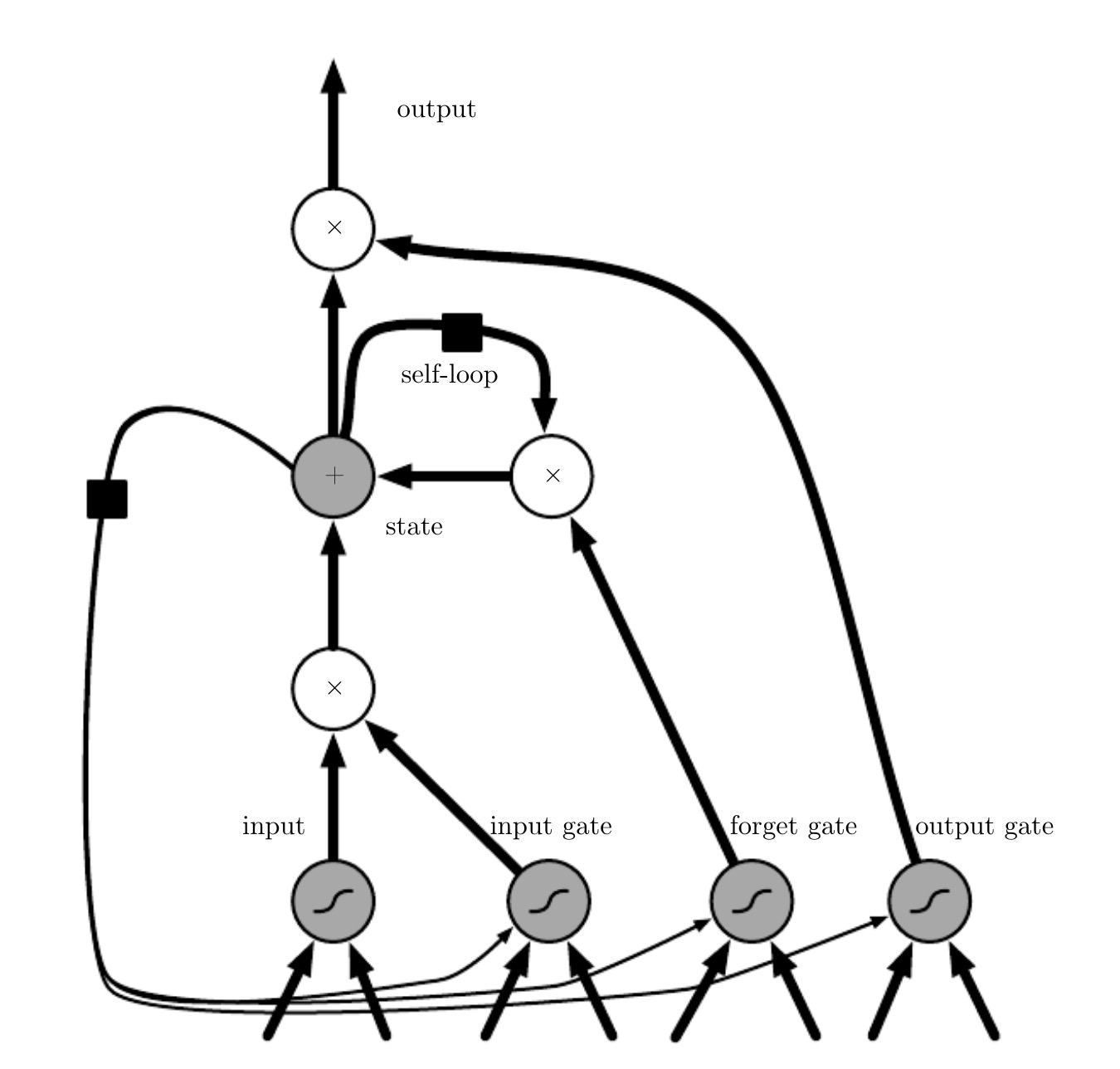 (Figure 2: LSTM structure. Taken from Chapter 10 of the book[1].)
(Figure 2: LSTM structure. Taken from Chapter 10 of the book[1].)
In an LSTM, the “hidden state” is split into two components:
- Cell State ($c_t$): This acts as the long-term memory of the network. It can carry information over many time steps with minimal distortion.
- Hidden State ($h_t$): This is often referred to as the short-term memory or the “output” hidden state. It is a filtered version of the cell state and is what is passed on to the next layer or used for predictions at the current time step.
The key innovation of LSTMs lies in the gates, which are neural networks in themselves that learn to control what information is added to or removed from the cell state. There are three main gates:
- Forget Gate: Decides what information from the previous cell state ($c_{t-1}$) should be discarded.
- Input Gate: Determines which new information from the current input ($x_t$) and previous hidden state ($h_{t-1}$) should be stored in the current cell state.
- Output Gate: Controls what information from the current cell state ($c_t$) is passed on to the new hidden state ($h_t$).
This gating mechanism allows LSTMs to selectively remember or forget information, enabling them to capture and maintain long-range dependencies in data much more effectively than simple RNNs.
To conclude, hidden state in RNN and LSTM means the sequential information passing between different time steps.
Transformer: A Parallel and Contextual Representation
The Transformer architecture, introduced in the paper “Attention Is All You Need,”[2] marked a paradigm shift. It completely dispenses with the recurrent structure of RNNs and LSTMs. Instead of processing a sequence step-by-step and maintaining a hidden state that evolves over time, the Transformer processes the entire input sequence at once.
In a Transformer, the concept of a single, evolving hidden state is replaced by a set of contextualized embeddings. The term “hidden state” in the context of a Transformer typically refers to the output vector for each token at each layer of the model.
Here’s how it works:
-
Input Embeddings and Positional Encodings: The input sequence is first converted into a series of embeddings. This embedding is the initial, shallow representation of an input token (a word or sub-word). It is the first step in converting text into a numerical format that the model can process. Since the model doesn’t have a recurrent structure to understand the order of the tokens, positional encodings are added to these embeddings to provide the model with information about the position of each token in the sequence.
-
Self-Attention: The core of the Transformer is the self-attention mechanism. For each token in the sequence, self-attention allows the model to weigh the importance of all other tokens in the sequence when creating a new representation for that token. This means the representation of a word is not just based on the word itself but on its relationships with every other word in the sentence.
-
Multi-Layer Architecture: A Transformer is composed of a stack of identical encoder or decoder layers. The output of one layer (a set of contextualized embeddings for each token) serves as the input to the next layer. The “hidden state” of a Transformer can be seen as the output of any of these layers. The final layer’s hidden states provide the most contextually rich representations of the input tokens.
In essence, while an RNN’s hidden state is a summary of the past, a Transformer’s “hidden state” for a particular token is a rich, contextualized representation of that token, informed by the entire input sequence simultaneously. This parallel processing capability and the ability to capture complex relationships between all tokens have made Transformers the dominant architecture for a wide range of natural language processing tasks.
Summary
The evolution from RNNs to LSTMs and then to Transformers is a story of developing more sophisticated and effective memory mechanisms.
- The RNN’s hidden state is a simple, sequential memory that struggles with long-term dependencies.
- The LSTM’s hidden and cell states, regulated by gates, provide a more robust and controlled memory, capable of retaining information over longer sequences.
- The Transformer’s “hidden state”, in the form of contextualized embeddings generated through self-attention, represents a move away from sequential memory to a parallel, holistic understanding of the entire input sequence at once. This has unlocked new levels of performance and efficiency in processing sequential data.
We will detail the Transformer structure, with its positional encoding and attention mechanism in the next series of posts!
Reference and Figure source:
[1] Goodfellow, Ian, et al. Deep learning. Vol. 1. No. 2. Cambridge: MIT press, 2016.
[2] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[3] StackExchange https://datascience.stackexchange.com/questions/82808/whats-the-difference-between-the-cell-and-hidden-state-in-lstm